BANDF AD
AI/ML
IBM lays out recipe for turning enterprise storage into an AI prep engine
An IBM Redbook guide shows how to integrate Storage Scale ECE, IBM Fusion, and Big Blue's Content-Aware Storage (CAS) with Nvidia's AI Data Platform to provide "an active AI preparation engine that continuously processes unstructured data – making it AI-ready through GPU-accelerated semantic chunking, vectorization, and indexing."
IBM added content awareness to Storage Scale (CAS) in March last year to enhance its retrieval-augmented generation (RAG) capability, building on Nvidia's AI-Q blueprint and NeMo Retriever microservice. It also announced Storage Scale support for Nvidia's AI Data Platform reference design.
At that time, IBM said Storage Scale content awareness facilities would be embedded in the next update of IBM Fusion, generally available in the second quarter of 2025.
BANDF AD
IBM says that a challenge facing agentic AI systems is preparing the vast repositories of enterprise data – roughly 80 to 90 percent of which exists as unstructured documents, multimedia files, and other non-standardized formats – for consumption by AI systems. The Nvidia AI Data Platform (AIDP) "transforms traditional storage infrastructure from passive data containers into active AI preparation engines. By including GPU acceleration directly into the data path, Nvidia AIDP performs the complex operations required to make unstructured data AI-ready (including semantic chunking, vectorization, and continuous synchronization) as background processes invisible to end users."
The Redbook outlines how to implement Storage Scale Erasure Coding Edition (ECE), IBM Fusion, and IBM Content-Aware Storage (CAS) as a storage layer with Nvidia AIDP to enable this.
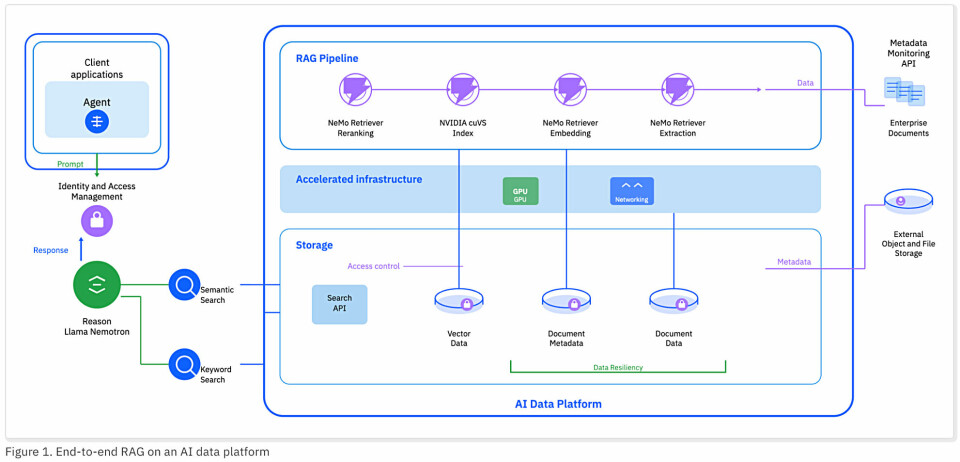
There are five basic components:
BANDF AD
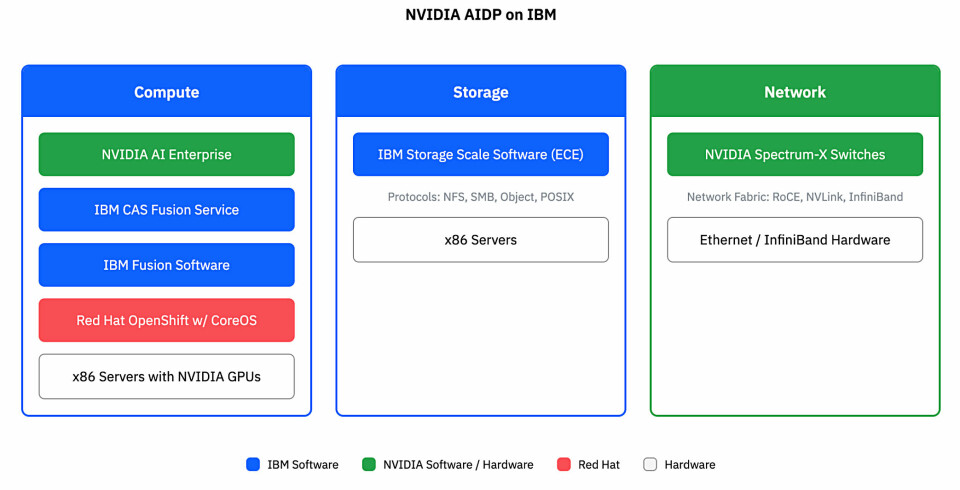
- x86 compute servers with Nvidia RTX PRO 6000 Blackwell Server Edition GPUs, Nvidia BlueField-3 DPUs (data processing units), and Nvidia ConnectX-7 or ConnectX-8 SuperNICs
- IBM Fusion software, which provides the OpenShift-based Kubernetes foundation for building the Nvidia AIDP
- IBM Storage Scale ECE system, which enables concurrent multi-GPU data access, eliminating I/O bottlenecks for real-time Nvidia AIDP updates and retrieval
- IBM Fusion Content-Aware Storage (CAS), which provides real-time data updates to Nvidia AIDP, eliminates silos for faster GPU inference, and enforces existing data source access controls in the RAG pipeline
- Nvidia Spectrum-X, which provides high-bandwidth, low-latency connectivity for rapid data transfer between IBM Storage Scale and IBM Fusion systems
This is how they are positioned in an AIDP system:
IBM says Storage Scale ECE is software-defined storage that features a high-performance parallel file system designed to eliminate data I/O bottlenecks. It can keep GPUs continuously fed with data for real-time inference, RAG workflows, and agentic AI applications. Storage Scale's Global Data Platform architecture presents dispersed data sources in a single namespace to Nvidia GPUs, whether data resides natively in Storage Scale or is accessed from external storage through Active File Management (AFM). Storage Scale's parallel file system delivers concurrent, high-bandwidth data access for AIDP workloads. Multiple GPUs simultaneously retrieve vector embeddings, document chunks, and knowledge base content without I/O contention, enabling RAG pipelines to scale linearly as compute resources grow.
Storage Scale ECE supports POSIX for traditional file system access, S3 for object storage compatibility, NFS and SMB for network file sharing, and CSI (Container Storage Interface) for Kubernetes environments. It also supports Nvidia’s GPUDirect Storage (GDS), with a direct memory access (DMA) path between the Storage Scale file system and GPU memory.
BANDF AD
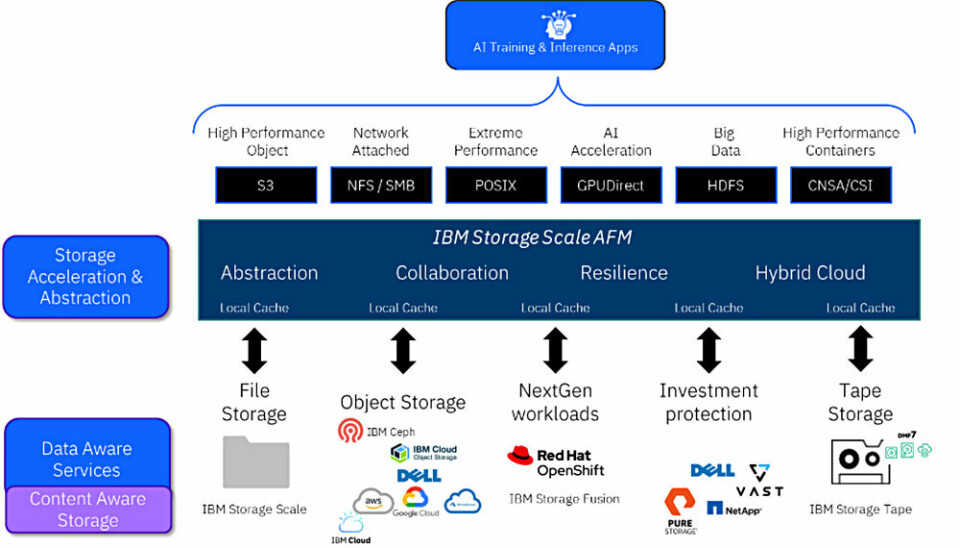
Storage Scale Active File Management (AFM) is a distributed caching feature that establishes a global, unified data platform and namespace across geographically dispersed IBM Storage Scale clusters and third-party NFS and cloud object storage sources. By allowing a local cluster (the "cache") to fetch and store copies of remote data (the "home"), AFM masks network latency and delivers high-speed, local access to data for remote users and AI applications.
Fusion CAS enables zero-copy ingestion and incremental vector database updates from unstructured sources, reducing data movement, latency, and operational complexity. In an AIDP implementation, Fusion CAS rearchitects the retrieval-augmented generation (RAG) pipeline by executing critical data-preparation steps in the storage layer, which minimizes AI inference latency and resource costs. The IBM Fusion CAS RAG workflow in Nvidia AIDP operates in two phases: the data ingestion/preparation flow and the retrieval/query flow. It provides a continuous and automated process to index and vectorize data as it arrives. Extracted content is chunked and converted into high-dimensional vectors (embeddings) using an Nvidia embedding NIM microservice. The system stores these vectors in a Fusion CAS-managed vector database on Storage Scale ECE.

When a user or AI agent asks a question, Fusion CAS accelerates and secures context retrieval. Fusion CAS's hardware-accelerated metadata processing and real-time incremental updates translate to lower latency for AI inference.
This Redbook does not cover the KV cache area. We expect an updated version will embrace KV caching with a context memory appliance and software added to this scheme. The Redbook is available as a downloadable PDF here.