BANDF AD
Nvidia and its partners' KV Cache extenders
Nvidia upset the AI inferencing memory KV Caching applecart with its latest CMX concept and STX reference architecture at the GTC 2026 event. Suppliers like VAST Data had their way forward eased. Others like Hammerspace and WEKA, who had placed bets on using local SSDs in a GPU server, could be caught up or bypassed.
The whole KV caching area is complicated and obscured by product renaming, incomplete explanations and Nvidia invading the KV cache front-end storage array world with its CMX reference architecture JBOFs (Just Boxes of Flash). We set out our understanding of the CMX and STX world here and layout a description of how many storage suppliers are responding to it.
The KV cache
BANDF AD
A key-value cache (KV cache) is a mechanism used to store past Gen AI large language model (LLM) layers’ activations (keys and values) during inferencing. It allows LLMs to bypass recomputation of these activations, improving performance. The cache serves as a repository to “remember” previous information, the pre-computed key and value pairs, reducing the need to reprocess entire sequences repeatedly.
The memory-based KV Cache applies to the attention mechanism of a transformer model (LLM).
The concept of attention in the LLM context is important. Some words in a sentence have unclear or ambiguous meanings. For example, “When the depositor saw the bank he entered it.”
BANDF AD
The word "bank" could mean a financial institution or a river bank. The context is the word "bank" in this sentence includes the word "depositor." The LLM attention notion is that when the LLM looks at a word in the sentence to calculate its vectors, the model will take into account the other words in the sentence, and the presence of the word ‘depositor’ will cause the ‘bank’ vector to be weighted towards the financial institution context.
The LLM uses the attention concept in both its prefill and decode phase. As a reminder, natural language input to an LLM consists of words and punctuation. These become tokens and vectors are generated from the tokens. In the models prefill phase it processes all the input tokens at the same time in parallel. In the later decode phase, during text generation, the model processes one token at a time, predicting the next token based on all previous ones. Its iterative process is memory-bound.
As inference progresses, this context grows as new token parameters are generated, often exceeding available GPU memory. When older entries are evicted and later needed again, they must be recomputed, increasing latency. Agentic AI and long-context workloads amplify the problem by expanding the amount of context that must be retained.
Without caching, Inferencing would need to recompute the keys and values for all prior tokens at every step, which is an inefficient process.
BANDF AD
In a little more detail, the LLM’s attention layer computes relationships between input tokens (words, subwords or punctuation) using three items: queries (Q), keys (K), and values (V or vectors).
Keys (K) represent the “context” or features of each token in the sequence. Values (V) hold the actual content or information tied to those tokens. The KV cache is not storing individual numbers or simple lists. It's storing large, structured arrays (tensors) that hold the key and value representations for every previous token, at every attention layer and every attention head in the LLM.
By maintaining a KV Cache, the model only computes K and V for the new token at each step, appending them to the cache, and then uses the full set of cached KV pairs to compute attention scores with the current query (Q). This drastically reduces computational overhead.
The KV Cache is held in data blocks in a GPU’s high-bandwidth memory (HBM). When that is full and new KV pairs are generated they go into HBM and existing content is evicted. If it is needed again then it has to be recomputed, taking time. A KV Cache scheme extends the cache to include, first, the DRAM in the GPU server’s embedded x86 server, then local NVMe SSDs in that server (tier zero), and then external, network-linked NVMe SSDs. Each tier in this KV Cache scheme takes longer to access than the preceding tier, but, if enough tokens have to have their vectors recomputed then the recomputation time can be longer than the access time to that tier.
As LLMs deal with larger and larger requests then such KV Cache extension becomes mandatory.
The KV Cache concept, although not the term, was explained in the “Attention Is All You Need" paper in 2017 by Ashish Vaswani et al. from Google.

NVMe-based KV cache storage has to work across a spectrum from GPUs to GPU servers to GPU racks to clusters of GPU racks.
Nvidia, Dynamo and CMX
GPU and AI platform system supplier Nvidia supports KV cache extension with its Dynamo software and CMX scheme. Dynamo is a distributed inference framework for scaling reasoning/multi-turn workloads supporting KV cache offloading, from (GPU HBM to CPU DRAM to local SSD to networked storage). It features KV-aware routing defining routes to nodes with existing cache, low-latency transfers via its NIXL library, and integration with vLLM, TensorRT-LLM, etc. Nvidia had a 4-tier KV cache concept up until its GTX 2026 event in March:

Nvidia has moved to address growing KV cache capacity limits by standardizing the offload of inference context to NVMe SSDs through its Inference Context Memory Storage Platform (ICMSP), now known as CMX. Announced at CES 2026, ICMSP extended GPU KV cache into NVMe-based storage, with a 4-tier hierarchy, making NVMe-resident KV cache part of the context memory address space and persistent across inference runs. It is backed by Nvidia’s NVMe storage partners.
Nvidia says the CMX “platform establishes a new G3.5 layer, an Ethernet-attached flash tier optimized specifically for KV cache. This tier acts as the agentic long‑term memory of the AI infrastructure pod that is large enough to hold shared, evolving context for many agents simultaneously, but also close enough for the context to be pre‑staged frequently back into GPU and host memory without stalling decode. … The G3.5 tier delivers massive aggregate bandwidth with better efficiency than classic shared storage.”
The G3.5 tier can be seen as bridging the gap between the in-Pod rack G3 tier and the off-Pod G4 tier, and also as replacing the G3 tier (see below). Nvidia’s tech blog says: “Inference frameworks like Nvidia Dynamo use their KV block managers together with Nvidia Inference Transfer Library (NIXL) to orchestrate how inference context moves between memory and storage tiers, using ICMS as the context memory layer for KV cache. KV managers in these frameworks pre-stage KV blocks, bringing them from ICMS into G2 or G1 memory ahead of the decode phase.”

“At the compute node level, KV tiering spans GPU HBM, host memory, local SSDs, ICMS, and network storage, providing orchestrators with a continuum of capacity and latency targets for placing context. Tying it all together, Spectrum-X Ethernet links Rubin compute nodes with BlueField-4 ICMS target nodes, providing consistently low latency and efficient networking that integrates flash-backed context memory into the same AI-optimized fabric that serves training and inference.”
We’re told: “When combined with the Nvidia BlueField-4 processor running the KV I/O plane, the system efficiently terminates NVMe-oF and object/RDMA protocols.”
The KV cache software – CMX – has to apply to GPUs, GPU servers, and racks of GPU servers, which can be running many different simultaneous inference workloads. Each model/agent workload’s parameter set has to be managed and made available to the right AI model or agent running in the right GPUs, which may change as jobs are scheduled. This means there is a KV cache context metadata management task.
Nvidia says CMX boosts KV cache capacity and accelerates the sharing of context across clusters of rack-scale AI systems. Persistent context for multi-turn AI agents improves responsiveness, increases AI factory throughput, and supports efficient scaling of long-context, multi-agent inference.
CMX relies on Rubin GPU cluster-level cache capacity and Nvidia’s BlueField-4 DPU with a Grace CPU and up to 800 Gbps throughput. BF-4 will provide and manage hardware-accelerated cache placement to eliminate metadata overhead, reduce data movement and ensure secure, isolated access from the GPU nodes. Nvidia software products – such as the DOCA framework, Dynamo KV cache offload engine, and its included NIXL (Nvidia Inference Transfer Library) software – provide smart, accelerated sharing of KV cache across AI nodes.
Dynamo works across a memory and storage hierarchy, from a GPU’s HBM, through a GPU server CPU’s DRAM, to direct-attached NVMe SSDs and networked external storage. Nvidia’s Spectrum-X Ethernet is also needed, offering a high-performance network fabric for RDMA-based access to AI-native KV caches. Overall, Nvidia says, CMX will provide up to 5x greater power efficiency than traditional storage and enable up to 5x higher tokens-per-second counts
An Nvidia tech blog says: “Inference frameworks like Nvidia Dynamo use their KV block managers together with Nvidia Inference Transfer Library (NIXL) to orchestrate how inference context moves between memory and storage tiers, using ICMS as the context memory layer for KV cache. KV managers in these frameworks pre-stage KV blocks, bringing them from ICMS into G2 or G1 memory ahead of the decode phase.”
We’re told: “When combined with the Nvidia BlueField-4 processor running the KV I/O plane, the system efficiently terminates NVMe-oF and object/RDMA protocols.”
An Nvidia Solution Overview doc provides more information, as does an Nvidia blog.
STX
In Nvidia’s GTC event in March it announced its STX modular reference architecture to help implement CMX. STX enables enterprises, cloud and AI providers to deploy accelerated storage infrastructure capable of the long-context reasoning required for agentic AI.
The idea is to accelerate data delivery to GPUs from storage by front-ending the storage drives with the BlueField-4 (BF-4) DPU which accelerates storage IO and helps support KV Cache extension to BF-4-fronted SSDs. Without this BF-4 assistance and KV Cache extension. AI query and agent responsiveness would both suffer and GPUs could endure more idle time.

Jensen Huang, Nvidia CEO and founder, said: “AI systems that reason across massive context and continuously learn require a new class of storage. Nvidia STX reinvents the storage stack, providing a modular foundation for AI-native infrastructure that keeps AI factories operating at peak performance.”
STX is accelerated by the Vera Rubin accelerator and harnesses the storage-optimized BF-4 processor. It combines the Vera CPU, BF-4, ConnectX-9 SuperNIC, together with Spectrum-X Ethernet networking, DOCA and Nvidia’s AI Enterprise software.
Nvidia claims its STX architecture also enables 4x higher energy efficiency compared with traditional CPU architectures for high-performance storage, and can ingest 2x more pages per second for enterprise AI data.
The first rack-scale implementation includes the CMX context memory storage platform.
Storage providers and manufacturing partners are building infrastructure using Nvidia’s STX modular reference designs for agentic AI, including AIC, Cloudian, DDN, Dell Technologies, Everpure, Hitachi Vantara, HPE, IBM, MinIO, NetApp, Nutanix, Supermicro, Quanta Cloud Technology (QCT), VAST Data and WEKA. (Hammerspace, Lightbits, Peak:AIO, and Pliops were not included in Nvidia’s CMX partner list although they all have existing KV cache extension schemes.)
Early adopters of STX for context memory storage include CoreWeave, Crusoe, IREN, Lambda, Mistral AI, Nebius, Oracle Cloud Infrastructure (OCI) and Vultr.
STX-based platforms will be available from Nvidia's partners in the second half of this year.
Comment
Here is a diagram showing B&F's understanding of Nvidia’s CMX KV cache scheme:
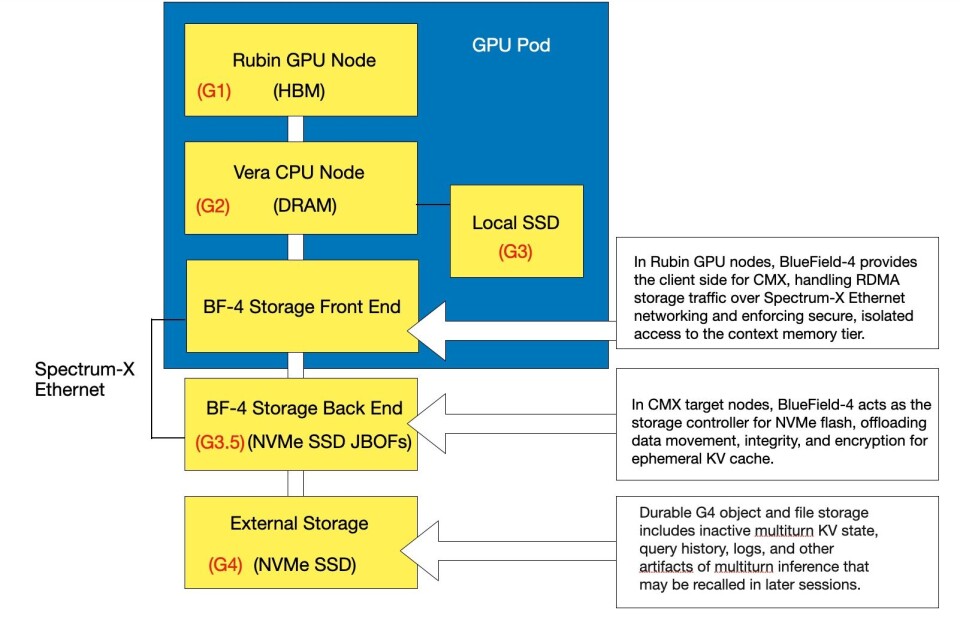
One thing we are not clear about is the KV cache data block flow from the G3.5 tier to the G2 tier. Is it direct or via an intermediate copy to the G3 tier? Vast Data (see supplier section below) says it’s direct. We have asked Nvidia to clarify this, and it said: "KV cache would typically flow from G1 --> G2 --> G3.5 and vice versa. As for G3, local SSDs in GPU servers may be hard to hot-swap, requiring GPU server downtime to replace them. NVIDIA CMX provides a much more scalable, performant, and resilient solution to managing KV cache at scale."
So the G3.5 tier replaces the G3 tier (local SSDs or tier zero in Hammerspace terms).
A second comment is that the G3.5 tier is a JBOF and, although it has SSDs with persistent storage, is used to hold ephemeral data; it’s a cache. Nvidia describes the G4 tier as durable, But not the G3.5 tier. Like all caches it can fill up and then data has to be evicted. We understand such evicted data goes to the G4 tier.
Thirdly, to implement a BF-4-controlled G3.5 tier requires storage controller logic to execute in the BF-4 DPU in the Vera CPU node. If a storage supplier, with a full storage data services stack is going to support this, it has to either separate out CMX functionality and port that to BF-4 or port its whole SW stack to BF-4, treating CMX as a logically separate operation from the rest of its activities. Vendors with disaggregated and scale-out storage SW architectures will have an easier job here. Think HPE with its Alletra X10000, Everpure with FlashBlade//EXA, NetApp and its AFX, and VAST Data.
Also the supplier has to decide what to do with Vera’s locally-attached SSDs. Hammerspace (Tier zero) and WEKA (Augmented Memory Grid) already use them in their pre-STX KV cache schemes.
The CMX/STX scheme is so new that, although most storage suppliers are planning to support it, they have no actual product availability yet.
A final point; CMX and STX apply to Nvidia's Rubin GPU racks, a niche market of unknown size. At present it doesn't apply to the AI inferencing market outside of the massive data centers housing the Rubin racks.
Suppliers
AIC
AIC expanded its Nvidia BlueField accelerated storage server portfolio with the F2032-G6 2U JBOF, optimized for accelerating AI inference by storing KV cache context. The platform supports up to 32 E3.S/L NVMe SSDs, enabling up to 8 PB of storage in a single 2U chassis using 15, 30, 60, 122 or 256 TB SSDs. It has a High Availability, dual-active node architecture with two or four BlueField-4 DPUs, and can also support ConnectX-9 SuperNICs. It supports DOCA microservices to deliver acceleration for Nvidia’s Inference Context Memory Storage Platform. January 2026.
Cloudian
Cloudian said it is building dedicated support for CMX within STX, enabling organizations to deploy high-speed KV cache infrastructure alongside — but architecturally separate from — their persistent data platforms.
With STX, these capabilities come together within a unified, NVIDIA-validated architecture. Cloudian customers deploying AI factories will be able to leverage STX-based configurations that span the full spectrum — from high-performance training data access through enterprise RAG to real-time agentic inference.
Cloudian is "actively working" with Nvidia to build and validate Cloudian solutions on the STX reference architecture. Its goal is to deliver integrated, production-ready configurations that allow enterprises to deploy AI-native storage infrastructure across all three STX system layers.
DDN
DDN says its software-defined AI data services are now aligned with Nvidia's STX reference architecture and run directly on BlueField-4 data processing units (DPUs). With this, DDN says it delivers direct GPU-to-data paths that reduce latency, lower power consumption, and increase effective GPU utilization across both training and inference workloads.
Its object-based Infinia OS accelerates inference performance and improves AI factory economics by eliminating data bottlenecks at scale, with:
- Up to 27x faster KV cache loading with a distributed acceleration fabric and deep Nvidia Dynamo integration
- Sub-millisecond latency that eliminates I/O stalls and maximizes GPU utilization at production scale
- Double-digit reductions in cost per token, materially improving inference economics
- Removes KV cache memory capacity as the critical path for large context windows and agentic AI workloads
- Vera Rubin architecture goals, enabling up to 10x lower inference token cost
Dell
Dell says it will support the STX modular reference design powered by Vera Rubin NVL72, BF-4, and Spectrum-X Ethernet networking that accelerates how organizations manage, process, and retrieve data for AI.
It says that Nvidia CMX context memory storage platform support and inference acceleration with KV Cache on shared storage across Dell’s PowerScale, ObjectScale and Lightning File System allows organizations to offload KV cache from GPU memory to Dell CMX Storage and high-speed shared network storage based on performance needs. This dramatically improves GPU utilization for long-context and agentic AI workloads, allowing AI systems to maintain context across extended interactions without exhausting GPU memory. This capability is essential for enterprises deploying AI agents that need to reference extensive historical data or maintain long conversation threads.
Everpure
An Everpure blog says: “We’re leveraging Nvidia STX reference architecture with FlashBlade//EXA by introducing a dedicated high‑performance context memory tier that enables efficient management of large KV caches and sustained inference throughput for agentic AI and long‑context reasoning workloads. … Everpure is developing new capabilities to support the Nvidia CMX context memory storage platform, built on Nvidia STX reference architecture within FlashBlade//EXA featuring high‑speed context retrieval and KV cache tiers.”
And: “With strong metadata management, efficient RDMA-enabled datapaths, and alignment with NVIDIA BlueField‑4-enabled storage controllers, FlashBlade//EXA is engineered to deliver the low‑latency access and sustained throughput required to prevent context‑retrieval stalls and maintain GPU saturation under heavy reasoning workloads.”
Everpure is actively developing configurations based on STX that combine:
- Everpure FlashBlade//EXA scale-out architecture for sustained AI data throughput
- A dedicated high-performance context memory tier for large KV cache management
- BlueField-4-enabled storage controllers designed for efficient AI data pipelines
- Architectures designed to support the scale and data demands of Vera Rubin-class AI factories.
Hammerspace
Hammerspace already provides its own take on KV caching by using the Vera CPU’s locally-attached SSDs, which it calls Tier zero. Nvidia announced Hammerspace as a partner in its Enterprise Inference partner network at GTC and that is the primary focus for Hammerspace directly with their formal programs right now. Hammerspace tells us that, "indirectly, the Hitachi Ventara resale relationship of Hammerspace gives us some access to the STK reference architecture program. We are doing a lot of work in all these areas but our focus right now is growing our leadership in the inference market as a first mover there."
Hitachi Vantara
Hitachi Vantara will support Nvidia's STX reference architecture to develop AI-native storage systems running on Vera Rubin GPUs, BF-4 DPUs, and Spectrum-X networking, and its AI software.
HPE
HPE will be supporting Nvidia’s STX rackscale reference architecture with its Alletra Storage MP X10000 to develop new AI storage offerings.

IBM
There is as yet no specific support for CMX or STX mentioned by IBM although it has a strong Nvidia partnership.
Lightbits and Scaleflux
Lightbits and ScaleFlux already support KV caching using Lightbits’ LightInferra cache SW reading data off ScaleFlux computational storage SSDs. They now have to decide whether to, and how to, support CMX in the STX architecture.
MinIO
MinIO announced its AIStor will support object data stores for Nvidia's new STX reference architecture, powered by Vera Rubin, the BlueField-4 DPU and Spectrum-X Ethernet networking.
AIStor runs natively inside the BlueField-4 DPU, which means, instead of operating on separate storage servers, AIStor runs directly within the networking layer of the system, placing storage directly in the AI data path, getting data to the GPUs faster. This scheme reduces the storage layers that can slow AI workloads. It eliminates the need for dedicated storage servers, making storage part of the AI fabric, and enabling fast, continuous access to context data required for RAG pipelines and agentic systems.
A Minio blog provides more information.
NetApp
NetApp will support NVIDIA STX to deliver a high-performance data engine with a specialized memory tier for KV-cache storage, improving power efficiency, throughput, and security. Leveraging NetApp data management capabilities in this new reference architecture, customers will be able to bridge the gap between massive AI compute and unstructured data storage by centralizing intelligent data handling.
Read more about NetApp AIDE here.
Nutanix
Nutanix Unified Storage delivers linearly scalable read/write performance for thousands of GPU clients. Nutanix says it provides a scalable, low-latency data fabric that maximizes GPU efficiency by providing a high-capacity tier for KV Cache offloading and support for S3 over RDMA and NFS over RDMA.
PEAK:AIO
PEAK:AIO has said it is solving AI inferencing model GPU memory limitations with CXL memory instead of offloading KVCache contents to NVMe flash drives. Its is developing a 1RU token memory product using CXL memory, PCIe gen 5, NVMe and GPUDirect with RDMA. Its its appliance enables:
- KVCache reuse across sessions, models, and nodes
- Context-window expansion for longer LLM history
- GPU memory offload via CXL tiering
- and Ultra-low latency access using RDMA over NVMe-oF
Nvidia’s CMX/STX offering enables other storage suppliers to have competing KV cache extension products, adding to its competition..
Pliops
Key-value accelerator card provider Pliops’ FusIOnX stack is an end-to-end AI inference offering based on its XDP LightningAI card. The XDP LightningAI is a PCIe add-in card and functions as a memory tier for GPU servers. It is powered by ASIC hardware and software, and caches intermediate LLM process step values on NVMe/RDMA-accessed SSDs. Pliops has yet to publicly respond to Nvidia’s CMX and STX schemes.
As with PEAK:AIO, Nvidia’s CMX/STX offering enables other storage suppliers to have competing KV cache extension products.
QCT

The #QuantaPlex S26F-2U is an CMX server with Al-native storage enabled by BF-4 to extend GPU memory across the POD with high-density NVMe storage and ultra-high-speed networking. Apart from it having BF-4, detailed configuration information is not available.
Supermicro

Supermicro unveiled a BF-4 STX Storage Server to Improve AI inference performance and built on the STX reference architecture for AI storage. The BF-4 STX storage server combines Nvidia’s Vera CPU and ConnectX-9 SuperNIC. There is no detailed configuration information about this server.
VAST Data
VAST’s CMX implementation has its CNode software running inside a GPU server’s BF-4, enabling zero-copy from a remote SSD to GPU memory, and virtio-fs provides the control-plane interface into the GPU host. (This suggests that ICMS will still use a file interface here.) The KV cache data blocks are stored in the G3.5 JBOFs - VAST D-nodes - with local BF-4s linked to the GPU server’s BF-4s.

There is no mention here of data blocks from the DNode JBOFs (G3.5 layer) being written into the Vera CPU’s local SSDs (G3 layer). They go straight into Vera’s DRAM (G2 layer), as a VAST diagram illustrates:

VDURA
VDURA announced the availability of Remote Direct Memory Access (RDMA) capability, the upcoming first phase of its Context-Aware Tiering technology planned for later this year. The initial phase introduces:
- Extended DirectFlow Buffer to Local SSD: Extends the DirectFlow buffer layer to local NVMe SSD, reducing dependency on network storage for hot data and minimizing latency for active AI workloads.
- KVCache Writeback for Persistence SLA: Intelligent writeback of KVCache data ensures only persistence-critical data is written back to durable storage, minimizing unnecessary I/O while maintaining SLA compliance for AI inference pipelines.
- Context Cache Tiering: A unified Context Cache Tiering framework enables seamless, high-speed read and write access across local SSD and DRAM tiers at LMCache speed, supporting AI inference use cases including long-context language model serving and retrieval-augmented generation.
VDURA has not yet announced support for STX. It has a roadmap of additional Context-Aware Tiering capabilities planned through 2027, encompassing deeper application-directed data placement, expanded cross-node cache coherence, and broader hardware support for Nvidia BlueField-4 DPUs.
WEKA
WEKA’s Augmented Memory Grid is a purpose-built memory extension layer that alreadybpools and persists KV cache outside of GPU memory, keeping long-context sessions stable and concurrency high as inference workloads grow. First unveiled at GTC 2025 and generally available to NeuralMesh customers today, Augmented Memory Grid has been validated with Supermicro on Nvidia Grace CPUs and BlueField-3 DPUs.
WEKA has integrated its NeuralMesh software with Nvidia’s STX reference architecture, and it will support STX to bring high-throughput context memory storage to agentic AI factories, making long-context reasoning seamless across sessions.
It reckons NeuralMesh/STX will deliver an estimated increase of 4-10x more tokens per second for context memory while supporting at least 320 GB read and 150 GB write throughput per second for AI workloads, more than double the throughput of conventional AI storage platforms.
A Report by WEKA's Chief AI Officer Valentin Bercovici says WEKA’s CMX adoption path has three stages:
Stage 1: backward-compatible KV cache offload on infrastructure customers already run today, using familiar network interfaces and traditional storage that relieves HBM pressure without replatforming runtimes.
Stage 2: pooled KV cache over higher-bandwidth context memory fabrics, where context starts behaving like shared DRAM-class infrastructure across GPU servers, delivering 6.5x higher agent token throughput per CapEx & OpEx, ahead of CMX-native availability.
Stage 3: leveraging measured 96% line rate Arm CPU performance on NVIDIA Grace, Augmented Memory Grid on Vera BF-4 client and server, will fully support CMX-native architecture where shared KV cache is a full platform, orchestrated by NVIDIA’s Dynamo framework, as first-class context infrastructure.
A diagram illustrates this concept;

WEKA says customers can build on existing systems now, capturing immediate gains in throughput, latency, and context capacity, while evolving toward CMX-native topologies as the STX ecosystem matures.
Bootnote
A Glen Lockwood blog has interesting observations about Nvidia’s CMX and STC ideas. The Nvidia ICMS section in his Digital Garden is also a good read. This article by Devansh, "How One Startup is Breaking Nvidia’s Memory Bottleneck", is a long and fascinating read.